大规模代码库的RAG实践
在这篇博客中,我将分享qodo(前身为Codium)如何通过构建一个优先考虑代码质量和完整性的生成式AI编码平台来解决RAG与具有有限上下文窗口的LLMs和大型复杂代码库之间的差距。

我们最近看到了很多很酷的生成式AI编码演示。有些人甚至会让你觉得一个勤奋的人工智能代理正在处理Upwork上的工作。尽管如此,Upwork的高手们无法与现实中的企业代码库相提并论,这些代码库拥有成千上万的仓库和数百万行(主要是遗留)代码。对于希望采用生成式AI的企业开发人员来说,上下文意识是关键。这就是检索增强生成(RAG)发挥作用的地方,然而,在大型代码库中实现RAG有其独特的挑战。
在企业层面使用RAG的主要障碍之一是可扩展性。RAG模型必须应对海量数据,并在不同的存储库之间导航架构复杂性,这使得上下文理解变得困难。在这篇博客中,我将分享qodo(前身为Codium)如何通过构建一个优先考虑代码质量和完整性的生成式AI编码平台来解决RAG与具有有限上下文窗口的LLMs和大型复杂代码库之间的差距。
1、将RAG应用于大规模代码库
RAG可以大致分为两部分:索引知识库(在我们的案例中为代码库)和检索。对于不断变化的生产代码库,索引不是一次性或周期性的工作。需要有一个强大的管道来持续维护新鲜的索引。
下图展示了我们的摄取管道,其中文件被路由到适当的拆分器进行分块,分块后增强了自然语言描述,并为每个分块生成向量嵌入,然后存储在向量数据库中。
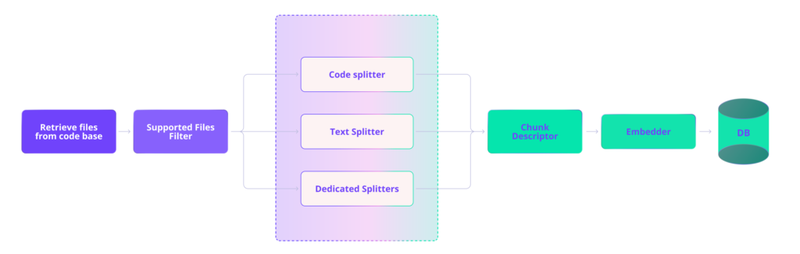
2、分块
分块对于自然语言文本相对简单——段落(和句子)提供了明显的边界点,用于创建语义上有意义的部分。然而,朴素的分块方法在准确地界定代码的有意义部分时存在问题,导致边界定义不清晰以及包含无关或不完整的数据。我们已经看到,提供无效或不完整的代码片段给LLM实际上会损害性能并增加幻觉,而不是帮助。
Sweep AI团队去年发布了一篇很棒的博客文章,详细介绍了他们分块代码的策略。他们开源了使用具体语法树(CST)解析器创建连贯分块的方法,该算法后来被LlamaIndex采用。
这是我们起步的基础,但我们遇到了一些问题:
- 尽管有所改进,分块仍然不总是完整的,有时会遗漏关键上下文,如导入语句或类定义。
- 可嵌入分块大小的硬限制并不总是允许捕获较大代码结构的完整上下文。
- 该方法没有考虑到企业规模代码库的独特挑战。
为了解决这些问题,我们开发了几种策略:
2.1 智能分块策略
Sweep AI实现了使用静态分析的分块,这是对先前方法的巨大改进。但在当前节点超过令牌限制并开始将其子节点分割成块而没有考虑上下文的情况下,他们的方法并不是最优的。这可能导致在方法或if语句中间断开分块(例如,“if”在一个块中,“else”在另一个块中)。
为了缓解这一点,我们使用特定于语言的静态分析递归地将节点划分为更小的块,并执行回溯处理以重新添加任何已删除的关键上下文。这使我们能够创建尊重代码结构的分块,将相关元素放在一起。
from utilities import format_complex
class ComplexNumber:
def __init__(self, real, imag):
self.real = real
self.imag = imag
def modulus(self):
return math.sqrt(self.real**2 + self.imag**2)
def add(self, other):
return ComplexNumber(self.real + other.real, self.imag + other.imag)
def multiply(self, other):
new_real = self.real * other.real - self.imag * other.imag
new_imag = self.real * other.imag + self.imag * other.real
return ComplexNumber(new_real, new_imag)
def __str__(self):
return format_complex(self.real, self.imag)
朴素分块:
def __str__(self):
return format_complex(self.real, self.imag)
我们的分块:
from utilities import format_complex
class ComplexNumber:
def __init__(self, real, imag):
self.real = real
self.imag = imag
# ...
def __str__(self):
return format_complex(self.real, self.imag)
我们的分块系统始终将类方法的关键上下文保持在一起,包括任何相关的导入语句以及类定义和初始化方法,确保AI模型拥有理解并处理此代码所需的所有信息。
2.2 在分块中维护上下文
我们发现嵌入较小的代码块通常能带来更好的性能。理想情况下,您希望拥有尽可能小的代码块,同时包含相关上下文——任何无关的内容都会稀释语义含义。
我们旨在使代码块尽可能小,并设置大约500个字符的限制。大型类或复杂的代码结构往往超出这个限制,导致代码表示不完整或碎片化。
因此,我们开发了一种灵活的分块系统,确保关键上下文(如类定义和导入语句)包含在相关的代码块中。
对于一个大型类,我们可能会为每个方法单独创建嵌入索引,但每次方法块都包含类定义和相关导入语句。这样,当检索到特定方法时,AI模型能够获得理解并处理该方法所需的完整上下文。
2.3 不同文件类型的特殊处理
不同的文件类型(例如代码文件、配置文件、文档)需要不同的分块策略来保持其语义结构。
我们为各种文件类型实施了专门的分块策略,特别注意像OpenAPI/Swagger规范这样的复杂、相互关联的结构。
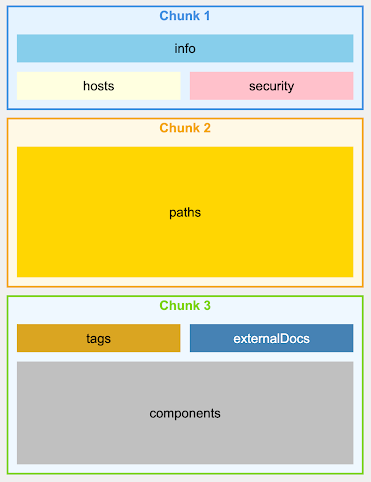
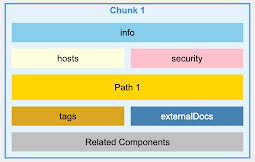
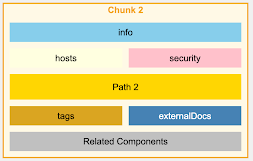
对于一个OpenAPI文件,我们不会按行或字符进行分块,而是按端点进行分块,确保每个块包含特定API端点的所有信息,包括其参数、响应和安全定义。
OpenAPI v3.0 – 朴素分块
OpenAPI v3.0 – 智能分块
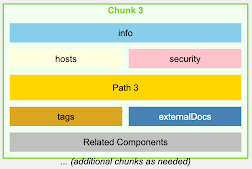
3、通过自然语言描述增强嵌入
代码嵌入通常无法捕捉代码的语义意义,特别是对于自然语言查询。
我们使用LLM生成每个代码块的自然语言描述。这些描述随后与代码一起嵌入,增强了我们检索与自然语言查询相关的代码的能力。
对于前面显示的map_finish_reason函数:
```python
# What is this?
## Helper utilities
def map_finish_reason( finish_reason: str,):
# openai supports 5 stop sequences - 'stop', 'length', 'function_call', 'content_filter', 'null'
# anthropic mapping
if finish_reason == "stop_sequence":
return "stop"
# cohere mapping - https://docs.cohere.com/reference/generate
elif finish_reason == "COMPLETE":
return "stop"
elif finish_reason == "MAX_TOKENS": # cohere + vertex ai
return "length"
elif finish_reason == "ERROR_TOXIC":
return "content_filter"
elif (
finish_reason == "ERROR"
): # openai currently doesn't support an 'error' finish reason
return "stop"
# huggingface mapping https://huggingface.github.io/text-generation-inference/#/Text%20Generation%20Inference/generate_stream
elif finish_reason == "eos_token" or finish_reason == "stop_sequence":
return "stop"
elif (
finish_reason == "FINISH_REASON_UNSPECIFIED" or finish_reason == "STOP"
): # vertex ai - got from running `print(dir(response_obj.candidates[0].finish_reason))`: ['FINISH_REASON_UNSPECIFIED', 'MAX_TOKENS', 'OTHER', 'RECITATION', 'SAFETY', 'STOP',]
return "stop"
elif finish_reason == "SAFETY" or finish_reason == "RECITATION": # vertex ai
return "content_filter"
elif finish_reason == "STOP": # vertex ai
return "stop"
elif finish_reason == "end_turn" or finish_reason == "stop_sequence": # anthropic
return "stop"
elif finish_reason == "max_tokens": # anthropic
return "length"
elif finish_reason == "tool_use": # anthropic
return "tool_calls"
elif finish_reason == "content_filtered":
return "content_filter"
return finish_reason我们可能会生成如下描述:
“标准化来自不同AI平台的完成状态的Python函数,将平台特定的原因映射为通用术语,如‘stop’、‘length’和‘content_filter’。”
然后将此描述与代码一起嵌入,从而改善对类似“如何跨不同平台规范化AI完成状态”的查询的检索效果。这种方法旨在解决当前嵌入模型的不足之处,即它们不是面向代码的,缺乏在自然语言和代码之间有效翻译的能力。
4、高级检索和排名
简单的向量相似性搜索常常会检索到不相关或上下文不正确的代码片段,特别是在大型且多样化的代码库中,有数百万个索引块。
我们实现了一个两阶段的检索过程。首先,我们从向量存储中执行初步检索。然后,使用LLM对结果进行过滤和排名,基于其与特定任务或查询的相关性。
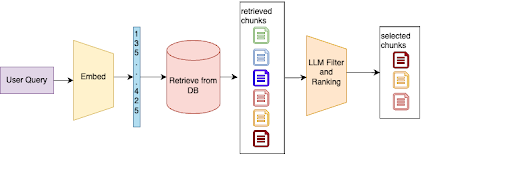
如果开发人员查询“如何处理API速率限制”,我们的系统可能会首先检索几个与API调用和错误处理相关的代码片段。然后,LLM根据查询分析这些片段,在上下文中对那些专门处理速率限制逻辑的片段进行排名,并丢弃不相关的结果。
5、扩展企业仓库的RAG
随着存储库数量增长到数千个,如果对每个查询都搜索所有存储库,检索会变得嘈杂且效率低下。
我们正在开发存储库级别的过滤策略,以在深入每个代码块之前缩小搜索范围。这包括“黄金存储库”的概念——允许组织指定符合最佳实践并包含良好组织代码的具体存储库。
对于关于特定微服务架构模式的查询,我们的系统可能会首先基于元数据和高级内容分析识别出最有可能包含相关信息的前5-10个存储库。然后它执行详细的代码检索。在这些存储库中搜索,显著减少噪声并提高相关性。
6、RAG基准测试与评估
由于缺乏标准化的基准,对代码的RAG系统性能进行评估具有挑战性。
我们开发了一种多方面的评估方法,结合了自动化指标和企业客户的实际使用数据。
我们使用了一种组合方法,包括相关性评分(开发人员实际使用检索到的代码片段的频率)、准确性指标(用于代码完成任务)以及效率测量(响应时间、资源使用)。我们还与我们的企业客户密切合作,收集反馈和实际性能数据。
7、结束语
为大规模企业代码库实现RAG提出了独特的挑战,这些挑战超出了典型的RAG应用范围。通过专注于智能分块、增强嵌入、先进的检索技术和可扩展架构,我们开发了一个系统,能够有效导航和利用企业规模代码库中包含的大量知识。
随着我们继续完善我们的方法,我们对RAG如何革新开发人员与大型复杂代码库交互的方式感到兴奋。我们认为,这些技术不仅会提高生产力,还会改善大型组织中的代码质量和一致性。
原文连接:RAG for a Codebase with 10k Repos
汇智网翻译整理,转载请标明出处
