OpenAudio S1:能哭会笑的TTS
从Fish-TTS升级而来的OpenAudio-S1,打败了ElevenLabs、Dia1.6B、Sesame-CSM-1B等其他模型,是情绪表达能力最强的TTS。

你知道最近AI语音变得多么厉害了吗?简直太吓人了。尽管市面上已经有各种各样的高端语音,但大多数听起来还是……嗯,就像喝了三倍浓缩咖啡后的Siri:机械感十足、过度兴奋、完全不考虑上下文。
但是你知道吗?一个新的开源冠军刚刚登场了——而且它不仅仅优秀。它是OpenAudio-S1级别的优秀。
让我们来剖析一下为什么OpenAudio-S1可能是你还没有尝试过的最好的文本转语音(TTS)模型,但绝对应该试试。
1、Fish-TTS → OpenAudio-S1
你听说过Fish-TTS,现在它已经升级为OpenAudio-S1。想象一下你最喜欢的地下乐队终于走上了主流舞台——但这次是积极正面的那种转变。他们带来了相同的创新核心,但如今更加精致、有力且性能更佳。
OpenAudio-S1是他们的新系列中的第一款,带来了在语音真实感、情感控制和多语言掌握方面的重大升级。
该模型以两种版本发布:4B和0.5B模型。
- S1(4B): 全尺寸旗舰模型,提供最丰富和细腻的表现。
- S1-mini(0.5B): S1的高度优化版本,专为资源优化的应用场景设计,同时不会显著影响质量。
架构:
- OpenAudio S1利用了Qwen3架构,并且本质上是一个原生的多模态模型,能够支持TTS、STT、TextQA和AudioQA(目前仅发布了TTS功能)。
- 音频编码和解码采用了类似Descript Audio Codec的架构,从头开始训练并增强了变压器以实现卓越的文本建模能力。
- 这两个模型都通过RLHF进行了训练——没错,就是那个驱动ChatGPT等聊天机器人的强化学习魔法。在这里,它被用来微调语音的细微差别。
2、语音控制:OpenAudio S1的情感与音频武器库
没有其他TTS模型能像OpenAudio S1一样拥有如此广泛的情感范围:
基本情绪:
(angry) (sad) (excited) (surprised) (satisfied) (delighted) (scared) (worried) (upset) (nervous) (frustrated) (depressed) (empathetic) (embarrassed) (disgusted) (moved) (proud) (relaxed) (grateful) (confident) (interested) (curious) (confused) (joyful)
高级情绪:
(disdainful) (unhappy) (anxious) (hysterical) (indifferent) (impatient) (guilty) (scornful) (panicked) (furious) (reluctant) (keen) (disapproving) (negative) (denying) (astonished) (serious) (sarcastic) (conciliative) (comforting) (sincere) (sneering) (hesitating) (yielding) (painful) (awkward) (amused)
语气标记:
(in a hurry tone) (shouting) (screaming) (whispering) (soft tone)
特殊音频效果:
(laughing) (chuckling) (sobbing) (crying loudly) (sighing) (panting) (groaning) (crowd laughing) (background laughter) (audience laughing)
3、突出亮点
让我们快速浏览一下真正实用的功能:
- 零样本/少样本TTS: 上传一段10到30秒的声音片段即可现场克隆。
- 多语言与跨语言支持: 输入英文、中文、日文、法语——无论什么语言,它都能发音。
- 无需音素烦恼: 不依赖音素,只需处理纯文本。
- 超快运行速度: 在笔记本GPU上接近实时运行。RTX 4060上为1:5的速度,RTX 4090上为1:15。
- WebUI+GUI支持: 无论是浏览器用户还是桌面爱好者,都可以使用。
- 部署就绪: 支持Linux和Windows的原生推理服务器(Mac版即将推出)。
4、对比测试
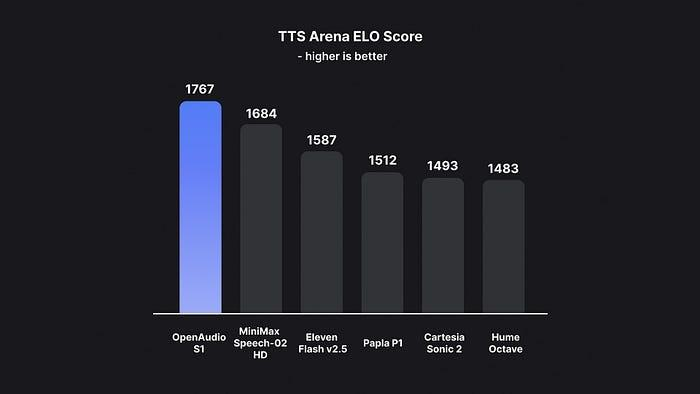
它甚至领先于闭源的TTS模型!
它不仅实现了世界领先的WER(词错误率)和CER(字符错误率),还在HuggingFace的人类主观评价中排名 #1。
5、结束语
OpenAudio-S1不仅仅是提高了标准——它重新定义了TTS的游戏规则。从捕捉原始情感到支持多种语言和语气,它将录音室级别的语音带到了你的指尖。
让它真正特别的是它是开源的、闪电般快速且异常易于使用。无论你是构建语音助手、配音视频还是创造沉浸式的音频体验,OpenAudio-S1都是你的终极工具包。
尝试一次——你会想知道以前是如何忍受那些机械声音的。
原文链接:OpenAudio S1 : TTS model that Laughs, Cries and every Emotion
汇智网翻译整理,转载请标明出处
