推理/微调速度对比:CPU vs. GPU
上周末,我有机会测试了多个GPU,包括最先进的Nvidia H100、RTX 5090、RTX 4090等。本文将总结它们在推理和微调任务上的性能。

从算法和模型中暂时休息一下,我们跳入了GPU的世界。上周末,我有机会测试了多个GPU,包括最先进的Nvidia H100、RTX 5090、RTX 4090等。在这篇博客文章中,我将总结它们的性能,并比较它们在AI特定任务中的加速效果,无论是LLMs的推理还是LLMs的微调。
如果你是GPU世界的新人,下面是一个简要的比较这些GPU如何预期与CPU相比:
H100 是AI和数据中心的强大工具——超级计算机的大脑。通常为企业拥有。 RTX 4090 是顶级的游戏和创作者GPU。最前沿的消费级GPU。 RTX 5090 应该比RTX 4090更快更炫酷,采用新的Blackwell架构。 T4 是免费的Google Colab GPU,不如上述的强。
在一个理想的世界里,每种GPU相对于CPU的预期提升如下:
H100: 🚀 ~100倍 5090(预计): ⚡ ~50倍 4090: 🔥 ~40倍 T4: 💡 ~10倍 CPU: 🐢 基线 所以,让我们开始吧。
但这是真的吗?让我们检查一下!
为了比较性能提升,我选择了两个任务:
- 使用LLM进行摘要
- 对小数据集进行LLM微调
为什么?虽然一些LLM更适合推理,而另一些可能更适合微调。因此,我选择了这两个不同的任务来测试这些GPU与CPU。
1、任务1 — 使用LLM进行摘要
在这个任务中,我使用了Google的T5大型LLM(大约7亿参数)对100篇随机文章进行摘要。重点不是查看输出的质量,而是每种硬件需要多长时间来完成摘要。除了使用的硬件(即CPU或GPU)之外,所有其他规格都保持不变。
以下是使用的代码:
from transformers import pipeline
import torch
import time
# 检测设备
device = 0 if torch.cuda.is_available() else -1
print("设备:", "GPU" if device == 0 else "CPU")
# 加载摘要器
summarizer = pipeline("summarization", model="t5-large", device=device)
# 创建虚拟“文章”(10K重复样本)
fake_article = "快速的棕色狐狸跳过懒惰的狗。" * 30
articles = [fake_article for _ in range(100)]
# 分批运行摘要
batch_size = 32
summaries = []
start = time.time()
print("开始摘要")
for i in range(0, len(articles), batch_size):
batch = articles[i:i+batch_size]
result = summarizer(batch, do_sample=False)
summaries.extend(result)
end = time.time()
print(f"在{end - start:.2f}秒内使用{torch.cuda.get_device_name(0)}完成了{len(articles)}篇文章的摘要")
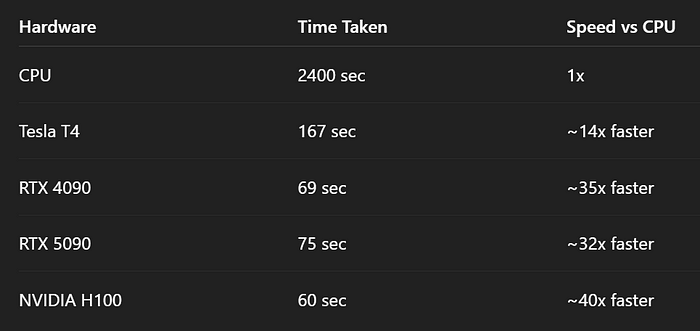
以下是使用5个硬件资源进行实验的结果:CPU(Tesla T4)、RTX 1590、RTX 4090和Nvidia H100。
2、任务2 — DistillBert微调
第二个任务是微调DistillBert,大约有7.5K条记录。与上面的实验类似,除了使用的硬件不同外,其他所有规格都保持不变。对于CPU,只训练了一个epoch,因为训练时间非常长,所以估计了5个epoch所需的时间。对于其他4个GPU,模型训练了5个epoch。
以下是使用的代码:
import time
import pandas as pd
import numpy as np
from datasets import Dataset
from transformers import (
AutoTokenizer,
AutoModelForSequenceClassification,
TrainingArguments,
Trainer,
)
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english" # 定义将要使用的预训练模型
classifier = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2) # 获取分类器
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
import pandas as pd
# 加载训练数据
train_path = 'train.csv'
df = pd.read_csv('train.csv')
print("数据集大小",len(df))
df = df.loc[:,["text", "target"]]
from sklearn.model_selection import train_test_split
df_train, df_eval = train_test_split(df, train_size=0.8,stratify=df.target, random_state=42) # 分层分割
from datasets import Dataset, DatasetDict
raw_datasets = DatasetDict({
"train": Dataset.from_pandas(df_train),
"eval": Dataset.from_pandas(df_eval)
})
tokenized_datasets = raw_datasets.map(lambda dataset: tokenizer(dataset['text'], truncation=True), batched=True)
tokenized_datasets = tokenized_datasets.remove_columns(["text", "__index_level_0__"])
tokenized_datasets = tokenized_datasets.rename_column("target", "labels")
from transformers import DataCollatorWithPadding, TrainingArguments, Trainer
import numpy as np
# 数据填充,用于训练时输入模型的批次数据
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
# 训练参数
training_args = TrainingArguments("test-trainer", num_train_epochs=5,
weight_decay=5e-4, save_strategy="no", report_to="none")
# 验证错误指标
def compute_metrics(eval_preds):
metric = evaluate.load("glue", "mrpc") # F1和准确率
logits, labels = eval_preds
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)
# 定义训练器
trainer = Trainer(
classifier,
training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["eval"],
data_collator=data_collator,
tokenizer=tokenizer,
compute_metrics=compute_metrics
)
# 开始微调
start = time.time()
trainer.train()
end = time.time()
print("使用{}训练时间".format(torch.cuda.get_device_name(0)), end-start)
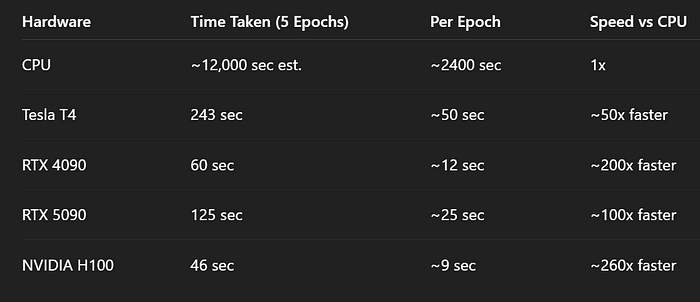
以下是实验结果。对于CPU,请注意这个数字是基于一个epoch的时间估算的,因为它花费了很长时间。
3、关键见解
上述实验得出了一些见解,这将帮助你更好地理解CPU与GPU之间的差异,并选择适合你的下一个GPU:
3.1 CPU在LLM任务中表现非常缓慢
让我们面对现实:使用CPU进行推理或微调就像试图在自行车比赛中获胜一样。你看到了:
- 使用CPU进行T5摘要需要24秒 vs T4需要1.6秒
- 微调DistilBERT需要约12,000秒(估计值) vs T4需要243秒
结论:即使是旧的T4 GPU也彻底击败了CPU。如果你在2025年还在用CPU进行LLM任务,要么你非常有耐心……要么你就被困在Kaggle内核中了。
3.2 T4是“基准GPU”——仍然令人尊敬
来自Google Colab的Tesla T4并没有让人失望,但仍保持了自己的地位。它提供了:
- 推理速度提升约15倍
- 微调速度提升约50倍
应用场景:入门级GPU训练/推理,非常适合学习和轻量级工作负载。但不要期待奇迹。
3.3 RTX 4090是性价比的最佳选择
这张卡特别在微调方面表现出色:
- 推理时间:69秒
- 微调时间:5个epoch需要60秒,或者每个epoch需要12秒
巨大200倍改进超过CPU!如果你认真对待LLMs,4090是你“物有所值”的最佳选择。
3.4 RTX 5090:更新≠更好(目前)
这是一个情节转折。5090比4090更新,理论上应该碾压它——但结果却是:
- 推理:75秒(比4090的69秒慢)
- 微调:125秒(比4090慢2倍以上)
为什么?
- 软件瓶颈:PyTorch、Hugging Face或CUDA驱动程序可能还没有完全针对5090架构进行优化。
- 我所知道的是,Nvidia没有提供任何AI基准测试结果,尽管他们一直在吹嘘5090的表现优于4090。
结论:不要仅仅因为新卡价格更高就期望它带来奇迹。始终为你的具体工作负载进行基准测试。
3.5 Nvidia H100:企业级巨兽,但尚未完全释放潜力
啊,是的,AI Mjölnir——H100。这东西是预训练的怪物。但在测试中:
- 推理:60秒(仅比4090快13%)
- 微调:总计46秒,或者每个epoch约9秒(最快!)
为什么性能平平?
- 开销:H100在超大批次大小和多GPU并行性下表现最佳。
- 软件不匹配:像Hugging Face Transformers这样的LLM库可能还没有充分利用H100的架构。
- 模型大小:你使用的DistilBERT和T5-Large——H100是为GPT-4规模的模型设计的。
底线:你需要正确的模型和正确的管道才能感受到H100的全部力量。否则,就像在停车场驾驶一辆F1赛车。
3.6 微调比推理获得更大的加速
别忘了这个黄金法则:
- 推理获得了约30–40倍的速度提升
- 微调获得了约50–260倍的速度提升
为什么?
- 微调是GPU密集型的:反向传播、优化步骤、内存缓存——它利用了你能提供的每一个CUDA核心。推理相对较轻。
3.7 硬件≠软件准备就绪
这是贯穿整个实验的主题
“大多数时候硬件已经更新了,但软件却没有。”
这一点至关重要。你可以花10,000美元购买一块GPU,但如果你的transformer库或CUDA驱动程序没有针对它进行优化,你就会被瓶颈限制。这对像5090这样的新卡或像H100这样的企业级巨兽来说尤其如此。
4、一些建议
经过这次实验,我学到了很多关于AI硬件方面的知识:
- 买今天支持的产品,而不是明天炒作的产品。 4090表现很好。
- 当新GPU推出时,检查Hugging Face论坛或PyTorch发布说明——支持总是滞后。
- 对于研究或小型训练,即使是Colab上的免费T4也能带你走很远。
- 除非是在测试代码或在后台写博客文章时,否则不要使用CPU。
5、结束语
如果你正在认真处理LLMs,那么硬件比以往任何时候都更重要。使用CPU就像是带着刀去参加激光战斗。即使是入门级的T4也能轻松击败它。然而,RTX 4090却找到了完美的平衡点:它强大、成熟,并且得到了现有库的良好支持。虽然RTX 5090看起来很棒,但软件生态系统还没有准备好——至少现在还没有。至于H100?毫无疑问是一头猛兽,但除非你运行的是GPT规模的模型并且有优化的管道,否则你就是在浪费一台超级计算机。
底线:根据你的工作负载购买,而不是追逐潮流。今天,4090统治着LLM领域。
原文链接:CPU vs GPU for AI : Speed Test
汇智网翻译整理,转载请标明出处
