打造自己的Devin, AI软件工程师
AI 软件工程师是一种 AI 助手,它可以查看 Git 存储库中的多个代码文件,并根据助手要执行的具体任务确定需要更改哪些文件。

“AI 软件工程师”的概念并不是一个很遥远的概念。
已经有一些技术在逐步简化软件工程的工作。
- Devin,号称是世界上第一个 AI 软件工程师,去年问世。
- Cursor,一个 VS Code 的替代品,因其在项目开发过程中轻松访问 AI 而越来越受欢迎。
- 如 Claude 和 GPT-4 等 LLM,可以帮助编写代码并修复代码文件中的错误。
随着越来越多的人类研究 LLM 推理能力,事情只会变得越来越容易。
1、AI 软件工程师 vs 普通 LLM
普通 LLM 和 AI 软件工程师有什么区别?LLM 也能写代码,不是吗?
在这种情况下,我们需要更精确地定义这些术语:
AI 软件工程师是一种 AI 助手,它可以查看 Git 存储库中的多个代码文件,并根据助手要执行的具体任务确定需要更改哪些文件。
例如,假设你在进行一个 AI 项目,并且需要修复一个问题,即每当用户选择 Mistral 模型时,AI 助手都无法正常加载。
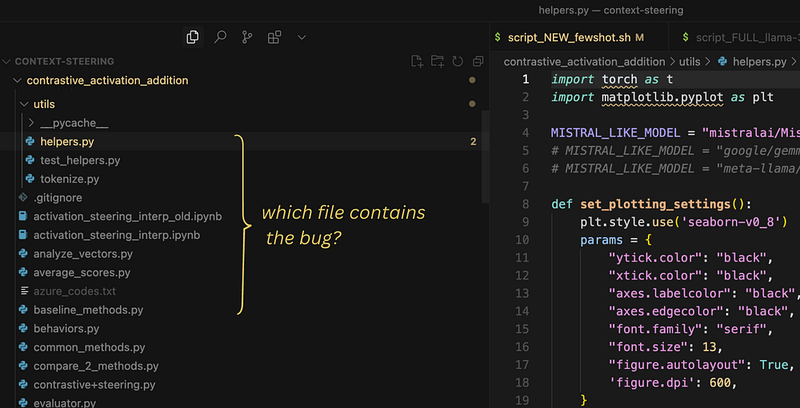
作为软件工程师,你需要首先找出哪个代码文件需要更改以修复该问题。例如,你可以检查加载模型的文件,看看是否可以在那里找到问题所在。如果相应的代码中涉及的一些变量或函数是从其他文件导入的,你也需要检查这些文件作为潜在的错误来源。
普通的 LLM 无法解决这个问题,因为我们不能每次提问时都把所有文件输入到 LLM 中。我们可能需要先自己找到文件,然后再将其传递给 LLM,要求它修复错误。
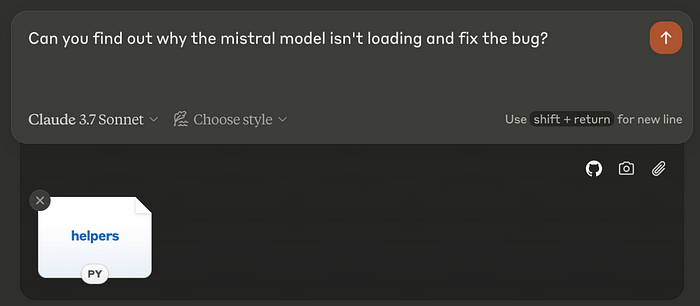
那么我们如何定义一个 AI 软件工程师呢?
一个 AI 软件工程师,就像一个普通的软件工程师一样,会按顺序执行增量 PR(拉取请求)来修复代码的某些方面。例如,如果我们想创建一个具有改进推理能力的 AI 助手,第一个 PR 可能涉及设置 AI 助手,第二个可能涉及设置训练工作流,依此类推。
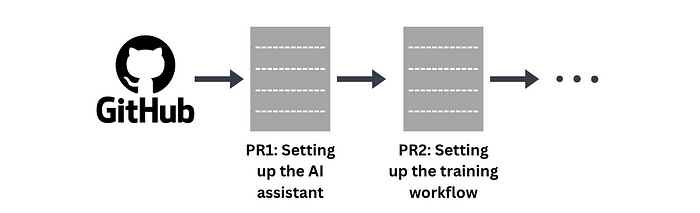
AI 助手需要为这些 PR 编写代码,无论是自行完成还是在用户的提示下完成。
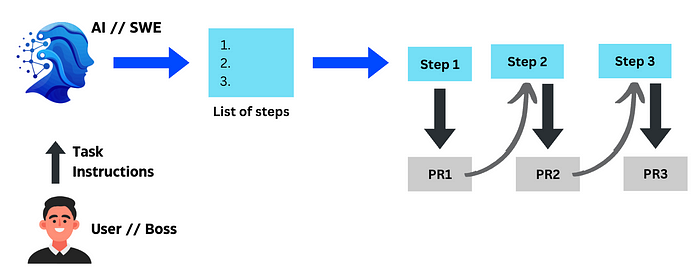
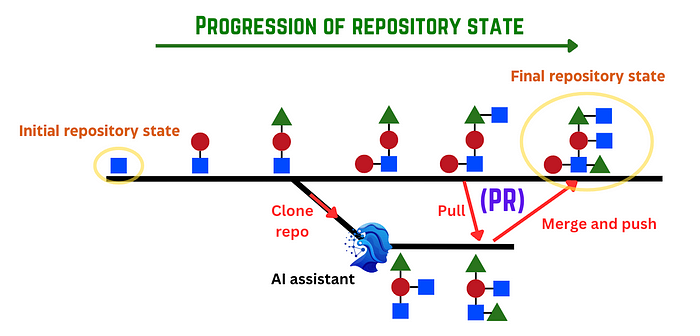
AI 软件工程师可能会采取一些任务来执行用户/老板的要求。(图片由作者提供)
2、如何创建一个 AI 软件工程师?
鉴于最近的 DeepSeek 模型,你可能会好奇 LLM 是否可以使用强化学习(RL)来提高其作为更好软件工程师的能力。我最近写了一篇关于 RL 训练技术多么通用的博客,如果你还没有看过的话,应该去看看。
RL 非常通用,这意味着在一个上下文(如提高推理能力)中应用它可以使其在其他上下文中表现得更好。这意味着 DeepSeek 所做的一切改进推理能力的方法也可能改善其在我们任务上的表现。
但我们能否通过明确使用软件工程示例来教它使其表现得更好?
首先,让我们定义一下任务。
任务
我们的目标是让 AI 助手根据代码库的当前状态和待完成的任务,自动对代码库进行必要的更改,就像软件工程师一样。
3、如何训练 AI 成为软件工程师
为了让 AI 完成同样的任务,我们将使用 DeepSeek 用于改进推理能力的相同强化学习 (RL) 训练流程。
强化学习是一种高度泛化的技术。这意味着,在一种情况下应用它(以改进推理能力),也可以让它在其他情况下表现得更好。这意味着 DeepSeek 为改进推理能力所做的一切,很可能也会提高它在我们任务上的表现。
但是,我们能否通过明确使用软件工程示例来训练它,使其变得更好呢?
为此,我们首先需要收集一些数据来训练 LLM。
为了实现这一点,我们首先需要收集一些数据来训练 LLM。
3.1 收集数据
为了训练 LLM,我们需要收集能够教会它在给定当前代码状态和所需功能的情况下做出更改的数据。
- 当前代码的状态,以及
- 需要更改的功能。
我们在哪里可以得到这些信息?
Git PRs。
Git PR(拉取请求)基本上是一个提议,即将一组更改从一个分支合并到另一个分支。当你在使用 GitHub 开发项目时,通常会对存储库进行更改,然后提交这些更改,并附上描述你完成的任务的提交消息。然后你会拉取存储库的当前状态并将你的更改与存储库合并。
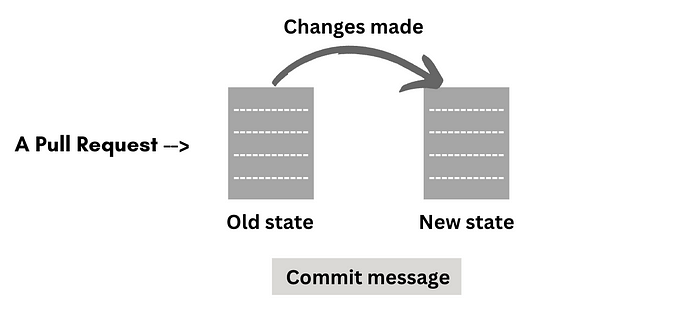
因此,一个拉取请求包含了我们所需要的所有信息——代码的先前状态、需要完成的任务以及完成该任务所做的更改。
因此,如果我们收集公共存储库上的数百万个拉取请求,我们应该有足够的信息开始教导 LLM 如何根据 要完成的任务 和 旧代码状态 来更改代码。
3.2 提示 LLM
现在我们有了数据集,我们需要弄清楚如何在训练过程中或推理过程中提示 LLM。
我们希望提供旧代码状态和来自数据集的任务,期望它输出需要进行的更改。
但是整个代码不能上传,所以我们可能会决定只提供两种类型的文件:
- 在提交之前和之后发生变化的文件
- 其他相关但未发生变化的文件
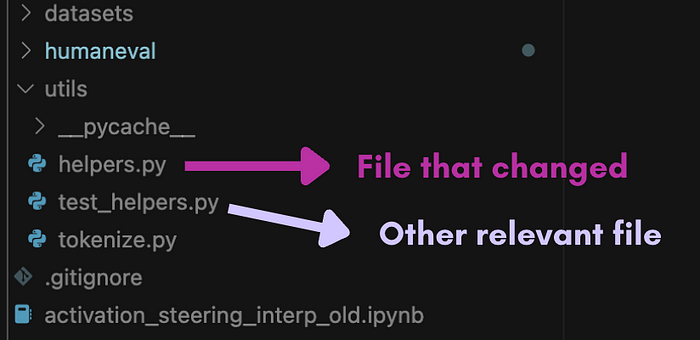
我们可以使用 LLM 根据文件名确定未发生变化的相关文件。想法是 LLM 不仅要知道需要更改哪些文件,还要知道不应该更改哪些文件,因此将这一点纳入训练过程对于帮助它学习至关重要。
3.3 定义奖励
说到具体的 RL 过程,我们如何定义奖励以激励 LLM 学习?
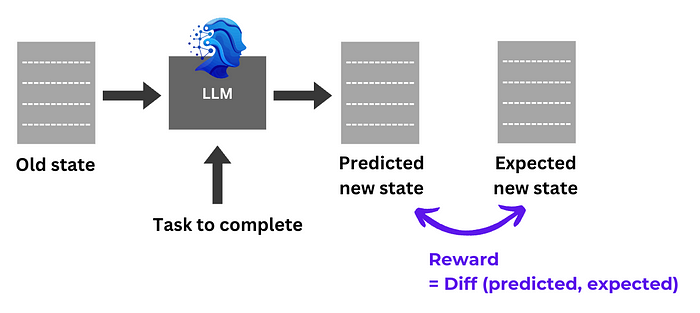
我们将以一种简单的方式定义奖励:量化 LLM 输出代码 和 PR 中实际新状态的文件 之间的差异。它们越相似,奖励越高。
3.4 训练过程
总体过程很简单:将每个数据点输入 LLM,提取输出,将输出与预期输出代码进行比较,并根据序列相似度提供奖励。LLM 会调整其策略以优化整体奖励。
4、我们如何进一步改进这个过程?
4.1 课程学习
研究表明,在 RL 训练循环中逐步增加问题难度有助于 LLM 更有效地学习,就像它会帮助学生更有效地学习一样。
由于目前我们是从 GitHub 上的公共存储库中随机选取 PR,我们可以根据提交的大小(即提交中所做的更改数量)对它们进行排序,假设涉及较少更改的提交比其他提交更容易推理。
或者,我们可以考虑另一种方法来判断每个 PR 中推理的难度,并按照难度递增的顺序排列数据点。
4.2 更清洁的数据集和奖励函数
在 RL 训练过程结束时提高 LLM 性能的一个主要瓶颈是数据集的清洁度。DeepSeek 和其他研究人员已经广泛展示了这一点。
- 数据集:这种方法的主要问题之一是数据本身的清洁度无法保证。我们理想情况下希望所有我们的 PR 都代表“良好的软件工程技能”,显然,如果我们从互联网上的公共存储库中获取所有 PR,这不可能实现。
- 奖励函数:如果存在多种解决问题的方法怎么办?如果 LLM 的方法与存储库中遵循的方法不匹配,即使 LLM 的方法实际上比存储库中的方法更好,LLM 也会得到负奖励。这是一个糟糕的信号,不能正确引导 LLM。
5、结束语
AI 软件工程师的概念并不遥远。它很可能很快就会开源,从而对世界各地的软件开发者高度可及。
我们讨论了一种可能的构建 AI 软件工程师的方法。这个过程本身可以通过各种方式变得更高效。用 RL 训练 LLM 仍然是一个新兴领域,有许多低垂的果实和大量的研究潜力。我个人今年进入这个领域,如果你感兴趣,我也建议你探索一下。
原文链接:How to make your own AI software engineer (like Devin)
汇智网翻译整理,转载请标明出处
