BitCPM4:1位LLM时代的到来
BitCPM4是mini CPM 4模型系列的一个变体,最近刚刚发布,专为边缘设备设计。与从头开始用三值权重训练的BitNet 1.5b不同,BitCPM4更像是MiniCPM4的量化版本。

几个月前,微软发布了BitNet 1.5b模型,并同时发布了一篇革命性的论文《1位LLM的时代》,其中他们介绍了通过将权重存储为三值权重来高度压缩LLM的方法。
现在,有一个值得期待的对手出现了,它就是BitCPM4,另一个LLM,能够将其权重/参数以三值权重的形式存储在一位中。尽管这两个模型的设计方式完全不同,但它们的功能是相同的。
1、什么是BitCPM4?
BitCPM4是mini CPM 4模型系列的一个变体,最近刚刚发布,专为边缘设备设计。与从头开始用三值权重训练的BitNet 1.5b不同,BitCPM4更像是MiniCPM4的量化版本。
BitCPM4不是从头开始训练的。它采用了一种巧妙的方式——从预训练的FP8模型开始,并通过两阶段训练方法将其逐渐转化为三值模型。
以下是关键点:
- 第一阶段: 使用学习率为
1e-2微调FP8检查点。 - 第二阶段: 在降低的学习率
5e-3下应用QAT(量化感知训练),并进行热身以确保稳定性。 - 令牌预算: 仅约40%的训练令牌用于QAT。
不需要4万亿个令牌。不需要数千个A100 GPU。只需要高效重用。
2、基准测试
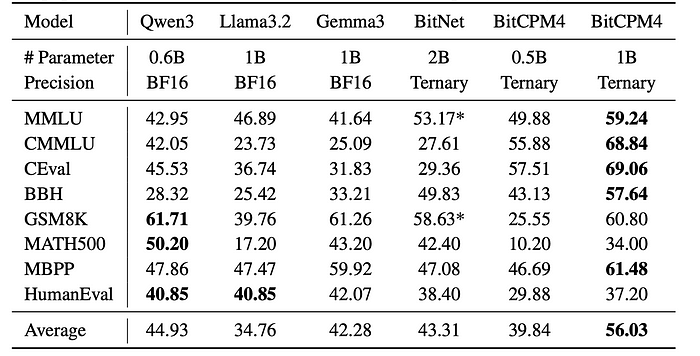
尽管BitCPM4的规模较小(0.5B和1B模型),但它表现得非常出色。
- BitCPM4–0.5B在标准基准测试(如MMLU和C-EVAL)上优于Qwen3–0.6B。
- BitCPM4–1B的表现与经过10倍更多令牌训练的BitNet–2B相当。
- 训练成本?仅为BitNet所花费的10%。
这不仅仅是好,而是令人惊讶地高效。
3、BitCPM4与BitNet 1.5B对比
即使BitCPM4是MiniCPM4的量化版本,它看起来也比BitNet 1.5B更好。以下是两者之间的详细差异,以及为什么你应该尽快选择BitCPM4。

重点在于:BitNet很棒,如果你有企业级基础设施并且希望充分利用边缘推理性能的话。而BitCPM4则是为我们其他人准备的——我们想要稳定、可部署的低比特LLM,而不会烧掉云预算。
4、BitCPM4为何有效
- 模块化。 可以使用预训练检查点,因此无需重新发明模型。
- 可扩展性。 从小模型开始,随着量化技术的成熟逐步扩展到更大的模型。
- 高效性。 不需要4T令牌的马拉松训练——只需通过QAT进行精准打击。
- 灵活性。 与现有工具链兼容,而BitNet则需要自定义运行时。
5、存在的一些问题
最小的BitCPM4模型在数学和代码密集型基准测试中表现不佳。这并不奇怪——三值权重加上小模型尺寸对符号推理来说是一个艰难的组合。但路线图很明确:扩大规模,保持QAT高效的技巧,你就能得到一个既精简又低比特且不妥协于智能的模型。
此外,大多数框架中的超低比特数学运算支持仍然不足。直到这些功能赶上,BitCPM4无法完全发挥其潜力。
6、结束语
如果BitNet是三值模型中的法拉利——快速、流畅、定制化——那么BitCPM4就是一辆永远跑不停的丰田车,油耗低,完成任务而不制造麻烦。在一个追逐1位梦想的世界里,BitCPM4是我们不知道自己需要的实用低比特路径。
该模型已开源,可以在HuggingFace上探索。
原文链接:BitCPM4 : The era of 1 bit LLMs is here
汇智网翻译整理,转载请标明出处
