基于AST的RAG代码分块技术
在RAG实现中,传统的分块方法忽略了代码结构,产生了语法不完整的片段。为了解决这个限制,我们可以使用代码的抽象语法树(AST)表示。

随着大型语言模型(LLMs)继续在各个行业中掀起革命,它们被广泛应用于各种应用中。代码生成是其中一项突出的应用。LLMs已经被用来生成代码片段、文档甚至整个程序。作为一个新兴领域,仍有许多挑战存在,其中三个关键挑战尤为突出:
- 幻觉现象:LLMs可能会生成语法正确但逻辑错误的代码(例如,使用不存在的API或忽略边缘情况)。
- 知识截止:模型受到其训练数据截止日期的限制,缺乏对新发展的认识,如更新的库版本或框架。这一局限性在编程中尤为重要,因为训练截止日期之后发生的API更改不会反映在LLM的回答中。
- 上下文长度:LLMs具有有限的上下文窗口,这在为大型项目或长函数生成代码时可能成为一个问题。这可能导致生成不完整或错误的代码。 此外,正如在[损失在中间]中所研究的那样,当上下文长度过长时,LLMs的性能会显著下降。
为了缓解这些挑战,检索增强生成(RAG)作为一种有效的解决方案应运而生。一个从这里改编的高层次RAG管道如下所示:
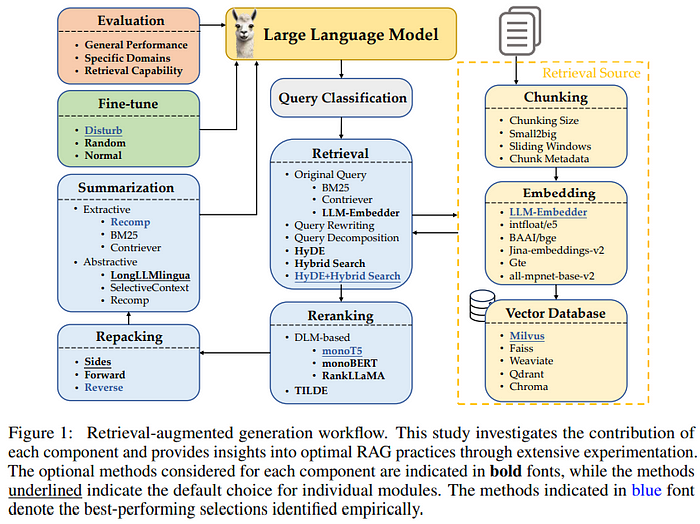
1、理解RAG用于代码生成
RAG通过两个主要组件运作:
- 检索器:搜索并提取相关知识来源的信息
- 生成器:通过LLMs处理这些信息以生成精炼的输出
这种架构为LLMs提供了额外的上下文进行推理,减少了幻觉现象,并通过启用访问最新信息来减轻知识截止的限制。可以实现一个RAG增强的LLM推理框架如下(改编自这里):
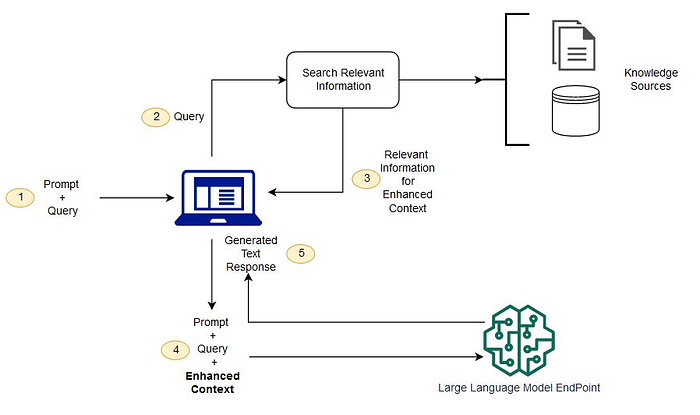
尽管有这些优势,上下文长度仍然是一个挑战。当内容超过一定长度时,LLMs的处理能力会显著下降。传统的分块策略在文本文档中表现良好,但在源代码中却表现不佳。
2、传统代码分块的问题
考虑这个简单的C++示例:
#include <iostream>
using namespace std;
void greet(string name) {
cout << "Hello, " << name << endl;
}
int main() {
greet("Alice");
greet("Bob");
return 0;
}
如果我们应用传统的分块方法(例如,块大小=50,重叠25)
from langchain.text_splitter import RecursiveCharacterTextSplitter
chunk_size = 50
text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=25, length_function = len)
chunks = text_splitter.split_text(code)
我们可能会得到:
+----------------------+------------------------------------+
| Chunk | 内容 |
+----------------------+------------------------------------+
| 1 | #include <iostream> |
| | using namespace std; |
|______________________|____________________________________|
| 2 | void greet(string name) { |
|______________________|____________________________________|
| 3 | cout << "Hello, " << name << endl; |
| | } |
|______________________|____________________________________|
| 4 | int main() { |
| | greet("Alice"); |
|______________________|____________________________________|
| 5 | greet("Alice"); |
| | greet("Bob"); |
|______________________|____________________________________|
| 6 | greet("Bob"); |
| | return 0; |
| | } |
+----------------------+------------------------------------+
问题显而易见:传统的分块方法忽略了代码结构,产生了语法不完整的片段。
3、基于AST的分块:更好的方法
为了解决这个限制,我们可以使用代码的抽象语法树(AST)表示。AST是一种树状结构,代表源代码的语法结构。基于AST的分块在有意义的边界上分割代码——例如函数定义或控制结构——确保每个块保持语法有效。
例如,“a = b + c”可以表示为一棵树,其中赋值运算符(=)是根节点,变量‘a’作为左子节点,加法表达式(b + c)作为右子节点。
4、使用Tree-Sitter实现基于AST的分块
Tree-sitter是一个强大的解析器,能够对源代码进行程序化分析:
4.1 设置Tree-Sitter
- 安装Tree-Sitter包
pip3 install tree_sitter
- 添加语言语法规则
pip3 install tree_sitter_cpp
4.2 使用Tree-Sitter
编译库后,我们可以解析代码:
from tree_sitter import Language, Parser
import tree_sitter_cpp
CPP_LANGUAGE = Language(tree_sitter_cpp.language())
parser = Parser(CPP_LANGUAGE)
code = '''
#include <iostream>
using namespace std;
void greet(string name) {
cout << "Hello, " << name << endl;
}
int main() {
greet("Alice");
greet("Bob");
return 0;
}
'''
tree = parser.parse(bytes(code, "utf8"))
探索解析后的树结构:
root = tree.root_node
for child in root.children:
print(child.type, " -> ", code[child.start_byte:child.end_byte])
输出:
preproc_include -> #include <iostream>
using_declaration -> using namespace std;
function_definition -> void greet(string name) {
cout << "Hello, " << name << endl;
}
function_definition -> int main() {
greet("Alice");
greet("Bob");
return 0;
}
4.3 使用Tree-Sitter进行代码分块
现在进入正题——通过提取语义上有意义的子树来进行代码分块:
terminal = [
'if_statement',
'while_statement',
'for_statement',
'for_range_loop',
]
def extract_subtree(subtree_root):
queue = [subtree_root]
subtree_nodes = []
ignore_types = ["\n"]
while queue:
current_node = queue.pop(0)
for child in current_node.children:
child_type = str(child.type)
if child_type not in ignore_types:
queue.append(child)
if child_type in terminal:
subtree_nodes.append(child)
return subtree_nodes
def extract_subtrees(tree):
root = tree.root_node
all_subtrees = []
queue = [root]
while queue:
current_node = queue.pop(0)
if str(current_node.type) in terminal:
all_subtrees.append(current_node)
else:
subtree = extract_subtree(current_node)
all_subtrees.extend(subtree)
children = [x for x in current_node.children]
queue.extend(children)
return all_subtrees
subtrees = extract_subtrees(tree)
我们已经定义了终端节点类型作为我们的分块边界。提取过程遍历AST并识别这些终端节点。
4.4 将AST节点转换为文本以生成嵌入
将节点转换回源代码文本:
src_texts = []
for subtree in subtrees:
if code[subtree.start_byte:subtree.end_byte] not in src_texts:
src_texts.append(code[subtree.start_byte:subtree.end_byte])
为每个代码块生成嵌入:
import torch
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")from transformers import AutoModel, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("Salesforce/codet5p-110m-embedding", trust_remote_code=True)
model = AutoModel.from_pretrained("Salesforce/codet5p-110m-embedding", trust_remote_code=True, torch_dtype=torch.float16, device_map={"":0})
model.config.model_type = 't5'
model = model.to_bettertransformer()
model.eval()
def get_embedding(texts, max_length=2048):
inputs = tokenizer(texts, return_tensors="pt", max_length=max_length, padding='max_length', truncation=True).to(device)
with torch.no_grad():
outputs = model(**inputs)
return outputs.cpu().detach()
embeddings = []
for src_text in src_texts:
embembedding = get_embedding(src_text)
embeddings.append(embedding)
4.5 存储和检索代码片段
在为每个代码片段生成嵌入之后,我们需要一种高效的方式来存储和检索它们。我们将使用hnswlib,这是一种适用于高维向量(如我们的代码嵌入)的快速近似最近邻搜索库。
import hnswlib
idlist = list(range(0, len(embeddings)))
dim = embeddings[0].shape[-1]
index = hnswlib.Index(space='cosine', dim=dim)
index.init_index(max_elements=len(embeddings), ef_construction=200, M=16)
index.add_items(src_emb, idlist)
# emb 是查询代码片段的嵌入
# k=5 返回最相似的 5 个代码片段
labels, distances = index.knn_query(emb, 5)
这创建了一个可搜索的索引,用于我们的代码嵌入,并通过计算向量表示之间的余弦相似度,实现了对语义上相似的代码片段的有效检索。labels变量包含最相似片段的索引,而distances指示每个匹配项与查询的接近程度。在实际应用中,我们可以使用这些检索到的代码片段来增强我们的代码生成提示。
4.6 局限性
细心的读者可能已经注意到,冗长的源代码可能会超出编码器和生成LLM的上下文长度限制。这是一个合理的担忧。一个实用的解决方案可以是采用滑动窗口策略,并在嵌入编码阶段进行平均处理。此外,在初始检索后,代码可以根据AST进一步分割,并根据其与查询(或分割后的查询)的相关性重新排序这些片段。
5、提升代码片段生成
在我们的示例中,我们展示了如何在基于AST的分块后使用CodeT5进行嵌入生成,实现了RAG管道中的检索器组件。这种方法可以通过扩展我们的子树提取逻辑以包括额外的终端节点类型和附近的代码片段来进一步增强。这种扩展将捕获更多上下文上有意义的代码片段,同时保持语法的有效性。我们将此作为读者的一个探索练习。
5.1 改进检索性能
检索过程可以通过高级技术如BM25或混合检索器进行优化。对于实际实现细节,AWS科学团队已在auto-rag-eval开源了全面的评估框架。使用他们的方法,我们可以实现基于BM25的检索,以获取任何给定提示的最相关代码片段,显著提高代码生成的质量。
5.2 使用Amazon Bedrock知识库优化存储
维护一个全面的代码片段索引可能是低效且计算密集的。因此,我们可以利用Amazon Bedrock的知识库(KB)进行高效存储和检索。AWS KB的关键优势在于它与部署在Amazon SageMaker上的LLM无缝集成。这种紧密集成使用户能够通过UI和API查询增强的LLM,从而促进增强代码片段的生成。有关实现细节,请参考AWS的开源存储库:Bedrock Access Gateway以及官方教程这里。
6、结束语
通过利用抽象语法树进行代码分块,我们解决了在代码生成任务中应用RAG的关键挑战。这种方法保留了代码片段的语法完整性,确保每个片段保持有效且有意义。该方法可以扩展为基于自定义标准生成片段,这可能提高生成代码的质量并减少幻觉。
原文链接:Enhancing LLM Code Generation with RAG and AST-Based Chunking
汇智网翻译整理,转载请标明出处
