AI驱动的食品标签阅读器
在这篇文章中,我将带你了解如何构建一个AI驱动的食品标签阅读器,可以让用户上传食品包装图片并自动提取结构化的营养事实和成分列表。

为什么理解我们的食物这么难?
在当今注重健康的世界上,消费者比以往任何时候都更加了解——然而营养标签仍然令人沮丧地难以阅读。细小的文字、令人困惑的化学名称、隐藏的糖分——关键细节往往埋没在技术术语中。
📉与此同时,肥胖、糖尿病和心脏病等生活方式疾病的发病率继续上升——其中许多与不良饮食习惯和超加工食品有关。
在印度,已经发起了强有力的运动来鼓励人们“读标签”,如“标签帕德加印度”或“包装袋转一圈,真相就出来”——但对于普通消费者来说,说起来容易做起来难:
- INS 322是什么意思?
- 多少添加的糖是“太多”?
- 这种零食比旁边的更健康吗?
1、问题
理解营养信息今天仍然需要时间、专业知识或对营销声明的信任。
在这篇文章中,我将带您了解我是如何构建一个AI驱动的食品标签阅读器的——这是一种工具,可以让用户上传食品包装图片并自动提取结构化的营养事实和成分列表。
使用CLIP、Gemma-3 12B VL模型和Streamlit,我创建了一个系统,将混乱、难以阅读的标签转换为简单易懂的数据——帮助消费者做出更明智的食物选择。
2、基础:来自真实平台的真实数据
但即使是最聪明的AI也无法解决没有正确数据的问题。
多年来,构建可靠食品标签阅读器的最大障碍之一就是缺乏良好、多样且最新的包装图像集中在一个地方。
这就是快速商务平台改变了这一切。
如今,像Blinkit、Zepto和Instamart这样的平台在法律上要求展示清晰的包装图像——包括营养成分表和成分列表——每种产品出售时都要显示。
这一规定意味着一个真实的、新鲜的包装数据金矿就在我们手中——每天更新,多样化,就像现实世界一样混乱。
这成为了构建和验证我的工具的基础。
3、系统架构概述
构建Pack2Facts涉及将视觉模型和LLMs整合到一个无缝的工作流中。
高层次流程如下所示:
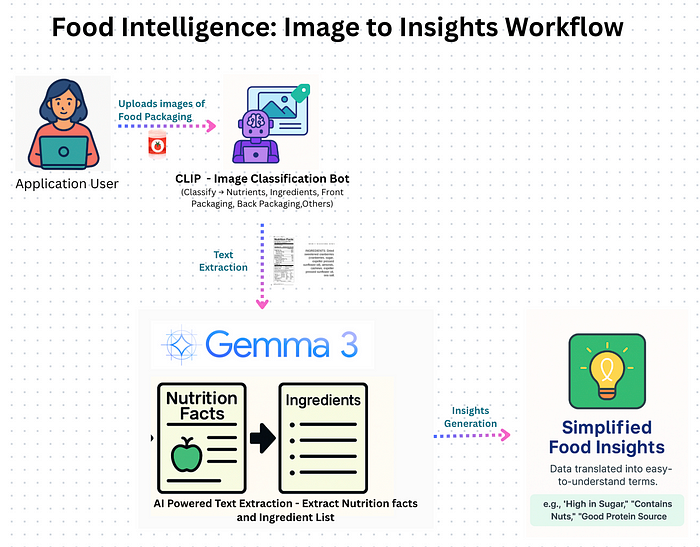
4、分步流程
4.1 图片上传
用户上传多个包装图片(来源于快速商务平台)
每个产品列表包含多张图片的幻灯片——不仅仅是单一的一张。
这些可能包含正面包装、品牌照片、营养信息和成分列表——所有这些混合在一起。

4.2 图像分类(CLIP零样本模型)
并非所有图片都有用——我们如何找到重要的图片?
为了准确提取有用的信息,我们首先需要识别相关的图片:
- 营养成分表
- 成分列表
为此,我们使用了CLIP——一种强大的零样本视觉语言模型。
为什么选择CLIP? CLIP学习了一个共享的空间用于图像和文本,使零样本分类成为可能。它无需重新训练即可将包装图片与描述如“营养标签”匹配——使其非常适合混乱的现实世界数据。
结果: CLIP自动将图片分类为:
✅ 营养成分
✅ 成分列表
❌ 无关图片(品牌、营销)
这确保了只有正确的图片会进入提取步骤。

4.3 预处理以提高提取效果
即使在识别出正确的图片(营养标签、成分列表)之后,许多现实世界的包装图片仍然是:
- 打印质量低对比度(红色可乐标签上的白色文字),
- 模糊不清,
- 受光线或压缩影响而失真。
这会降低任何试图提取结构化数据的视觉语言模型的准确性。
为了解决这个问题,我们利用传统的计算机视觉技术,使用OpenCV进行灰度转换、对比度增强和图像锐化。
如果没有这一步骤——即使是先进的模型也可能无法检测到关键元素——遗漏营养名称或将克与百分比混淆。
4.4 使用Gemma-3–12b-it-qat进行信息提取
一旦我们有了干净、预处理过的图片,下一个挑战就是提取结构化信息——比如:
- 营养成分(卡路里、脂肪、糖、钠)和RDA值。
- 成分列表,
- 份量大小
为此,我使用了Gemma-3,这是一种经过微调的视觉语言模型,能够处理结合图像理解和自然语言处理的任务,并通过LM-Studio在我的笔记本电脑上托管——确保数据安全和隐私。
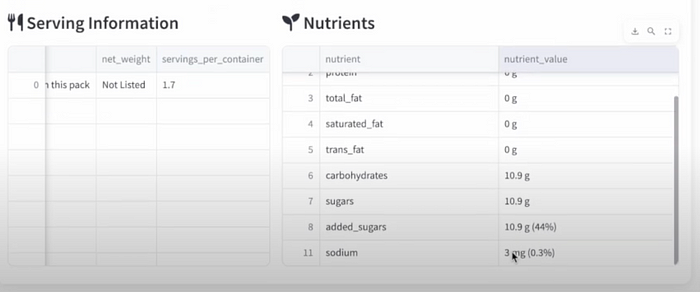
Gemma-3 VL模型以营养学家的方式阅读包装图片——从混乱、无序的标签中提取关键事实。
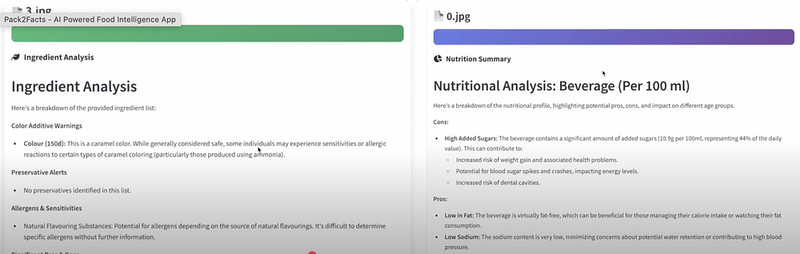
4.5 洞察生成:总结营养和成分
即使原始的营养表和成分列表被干净地提取出来——它们仍然对普通人来说难以理解。
仅仅给出像这样的数字:
- 钠:15毫克
- 脂肪:15克
- INS 322
……是不够的。
大多数消费者需要简单易懂的总结,以便做出更明智的决定——而不需要营养科学背景。
我们在这里利用开源LLM模型来总结营养和成分数据——扩展成分,突出食品消费的优缺点。
5、结束语
如今,数据无处不在——随着一切数字化,数据变得越来越丰富。
构建真正有价值的产品并不始于使用最大的模型或追逐最新趋势。
它始于理解数据——以及隐藏在其内的真正挑战。
理解数据揭示了模型为何失败——例如,白色文字在红色背景上如何混淆OCR——并指导更明智的设计决策。
真正的力量在于将正确的技术结合起来——无论是旧的还是新的——构建一个精心设计且有目的性构建的系统。
在Pack2Facts中,不仅仅是LLMs和视觉模型。
传统的图像处理技术——如灰度转换、对比度增强和锐化——在提高模型准确性、处理混乱的现实世界输入方面发挥了同样关键的作用。
好的AI系统不是靠追逐潮流建立的——它们是通过理解问题建立的。
最好的部分是?
Pack2Facts完全使用开源模型和工具构建
随着LLM变得越来越小、效率越来越高——最近发布的Gemma 3n能够在移动设备上运行——我们正迈向这样一个未来:这样的工具不仅适用于研究人员或公司。
它们可以掌握在普通消费者的手中——帮助人们从手机上做出更聪明、更快捷、更健康的选择。
原文链接:Can AI Decode What You Eat? Building a Food Label Reader
汇智网翻译整理,转载请标明出处
